HA集群概念
1、什么是高可用集群
高可用集群(High Availability Cluster,简称 HA Cluster),是指以减少服务中断时间为目的的服务器集群技术。它通过保护用户的业务程序对外不间断提供的服务,把因软件、硬件、人为造成的故障对业务的影响降低到最小程度。
2、高可用集群的衡量标准
要保证集群服务 100% 时间永远完全可用,几乎可以说是一件不可能完成的任务。比如,淘宝在这几年双十一刚开始的时候,一下子进来买东西的人很多,访问量大,都出现一些问题,如下单后却支付不了。所以说只能保证服务尽可能的可用,当然有些场景相信还是可能做到 100% 可用的。
通常用平均无故障时间 (MTTF:mean time to failure) 来度量系统的可靠性,用平均故障维修时间(MTTR:mean time to restoration)来度量系统的可维护性。于是可用性被定义为:HA=MTTF/(MTTF+MTTR)*100%。
具体 HA 衡量标准:
| 描述 | 通俗叫法 | 可用性级别 | 年度停机时间 |
|---|---|---|---|
| 基本可用性 | 2 个 9 | 99% | 87.6 小时 |
| 较高可用性 | 3 个 9 | 99.9% | 8.8 小时 |
| 具有故障自动恢复能力的可用性 | 4 个 9 | 99.99% | 53 分钟 |
| 极高可用性 | 5 个 9 | 99.999% | 5 分钟 |
3、高可用集群实现原理
高可用集群主要实现自动侦测 (Auto-Detect) 故障、自动切换 / 故障转移 (FailOver) 和自动恢复 (FailBack)。
简单来说就是,用高可用集群软件实现故障检查和故障转移(故障 / 备份主机切换)的自动化,当然像负载均衡、DNS 分发也可提供高可性。
3-1、自动侦测 (Auto-Detect)/ 故障检查
自动侦测阶段由主机上的软件通过冗余侦测线,经由复杂的监听程序,逻辑判断,来相互侦测对方运行的情况。
常用的方法是:集群各节点间通过心跳信息判断节点是否出现故障。
3-1-1、问题是:当有节点(一个或多个)和另外节点互相接收不到对方心跳信息时,如何决定哪一部分节点是正常运行的,而哪一部分是出现故障需要隔离的呢(避免集群脑裂)?
这时候通过法定票数(quorum)决定,即当有节点故障时,节点间投票决定哪个节点是有问题的,票数大于半数为合法。
- 票数: 每个节点可以设置票数,即决定节点在集群内是否合法(正常)的权限值,这个是可以有多有少的,例如有些节点的性能较好或有其他优势,可以设置较多的票数。
- 法定票数(quorum): 当一个节点能和另一个节点保持心跳信息,该节点就获取得了另一个节点的票数,该节点获得的所有票数就是法定票数。
3-1-2、比较特殊的是只有两个节点的集群,或两边票数相等
这时候可以借助另外的参考节点:
- ping node:两个节点的模式下,一旦其中一个节点发生故障,发生集群分隔以后,无法判定哪个节点不正常,但工作正常的节点一定是可以连到互联网,故正常的节点是可以跟前端路由通信,所以可以把前端路由当成第三个节点,如果可以 ping 通,那就说明自己是正常的,可以将对方隔离掉。
- qdisk: RHCS 不是使用 ping 节点来判断,而是使用一个共享存储的设备,节点按照心跳信息频率每隔一个信息频率时间就往磁盘里写一个数据位,如果设备每隔一个心跳时间间隔就更新一次数据位,就说明这个设备处于活动状态的,可以将对方隔离掉。
3-2、自动切换 / 故障转移(FailOver)
自动切换阶段某一主机如果确认对方故障,则正常主机除继续进行原来的任务,还将依据各种容错备援模式接管预先设定的备援作业程序,并进行后续的程序及服务。
通俗地说,即当 A 无法为客户服务时,系统能够自动地切换,使 B 能够及时地顶上继续为客户提供服务,且客户感觉不到这个为他提供服务的对象已经更换。
通过上面判断节点故障后,将高可用集群资源(如 VIP、httpd 等,下面详见)从该不具备法定票数的集群节点转移到故障转移域(Failover Domain,可以接收故障资源转移的节点)。
3-2-1、高可用集群资源(HA Resource)和集群资源类型
集群资源是集群中使用的规则、服务和设备等,如 VIP、httpd 服务、STONITH 设备等。类型如下:
- Primitive:主资源,在某一时刻只能运行在某个节点上,如 VIP。
- group:组,资源容器,使得多个资源同时停 / 启等,一般只包含 primitive 资源。
- clone:克隆,可以在多个节点运行的资源,例如 stonith 设备管理进程、集群文件系统的分布式锁(dlm)作为资源,应运行在所有节点上。
- master/slave:特殊的 clone 资源,运行在两个节点上,一主一从,如:分布式复制块设备 drbd(2.6.33 之后整合进内核了)。
3-2-2、转移到哪个节点
根据资源的倾向(资源粘性、位置约束的分数比较)进行转移;
资源的倾向(资源定位的依据):
A、资源粘性:资源对节点倾向程度,资源是否倾向于当前节点。score,正值倾向于当前节点(还要和位置约束结合)。
B、资源约束(Constraint):资源和资源之间的关系
- 排列约束 (colocation):资源间的依赖 / 互斥性,定义资源是否运行在同一节点上。score,正值表示要运行在同一节点上,负值则不可。
- 位置约束(location):每个节点都有一个 score 值,正值则倾向于本节点,负值倾向于其他节点,所有节点 score 比较,倾向于最大值的节点。
- 顺序约束(order):定义资源执行动作的次序,例如 vip 应先配置,httpd 服务后配置。特殊的 score 值,-inf 负无穷,inf 正无穷。
也就是说资源粘性定义资源对资源当前所在节点的倾向性,而位置约束定义资源对集群中所有节点的倾向性。
如 webip 的资源粘性为 100,位置约束对 node1 为 200,当 webip 在 node2 上时,node1 上线资源会转移到 node1,因为当前节点 node2 粘性 100 小于对 node1 的位置约束 200;
如 webip 的资源粘性为 200,位置约束对 node1 为 100,当 webip 在 node2 上时,node1 上线资源不会转移到 node1,继续留在 node2 上,因为当前节点 node2 粘性 200 大于对 node1 的位置约束 100。
3-3、自动恢复 / 故障回转 (FailBack)
自动恢复阶段在正常主机代替故障主机工作后,故障主机可离线进行修复工作。在故障主机修复后,透过冗余通讯线与原正常主机连线,自动切换回修复完成的主机上。
3-3-1、当排除故障后,是否要故障回转?
根据资源粘性和资源约束的设置,一般备用设备单纯只用于备份,性能低于主设备,所以当主设备恢复时应转回,但故障回转需要资源转移,会影响到正在使用的客户,过程代价较高,所以是否需要回转根据实际判断。
3-4、其他关注点
3-4-1、如果节点不再成为集群节点成员时(不合法),如何处理运行于当前节点的资源?
如果集群没有对其进行 Fecning/Stonith 隔离前,可以进行相关配置(without_quorum_policy),有如下配置选项:
- stop:直接停止服务;
- ignore:忽略,以前运行什么服务现在还运行什么(双节点集群需要配置该选项);
- Freeze:冻结,保持事先建立的连接,但不再接收新的请求;
- suicide:kill 掉服务。
3-4-2、集群脑裂(Split-Brain)和资源隔离(Fencing)
脑裂是因为集群分裂导致的,集群中有节点因为处理器忙或者其他原因暂时停止响应时,与其他节点间的心跳出现故障,但这些节点还处于 active 状态,其他节点可能误认为该节点 “已死”,从而争夺共享资源(如共享存储)的访问权,分裂为两部分独立节点。
脑裂后果:这时两个节点开始争抢共享资源,结果会导致系统混乱,数据损坏。
脑裂解决:上面 3-1-1、3-1-2 的方法也能一定程度上解决脑裂的问题,但完全解决还需要资源隔离(Fencing)。
资源隔离(Fencing):
当不能确定某个节点的状态时,通过 fencing 把对方干掉,确保共享资源被完全释放,前提是必须要有可靠的 fence 设备。
- 节点级别:这种就叫 STONITH,直接把对方的电源给切断,一般这种主机都是连接到电源交换机上的。
- 资源级别:同样需要依赖一些硬件设备来完成。比如节点通过光纤交换机连接到共享存储,通过把需要踢除出去的节点的光纤接口屏蔽来实现资源隔离,FC SAN switch(软件方式)。
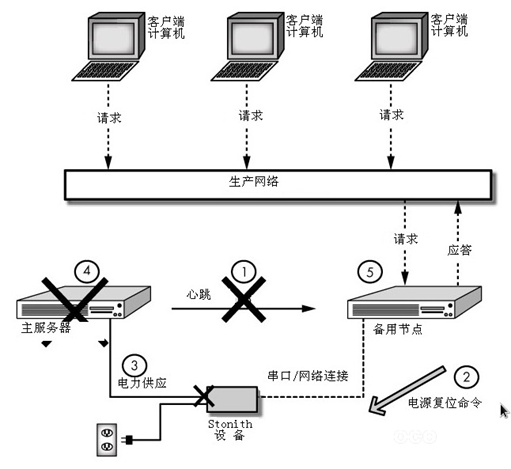
3-5、STONITH 组件
STONITH (Shoot The Other Node in the Head,”爆头”) 这种机制直接操作电源开关,控制故障节点的电源开关,通过暂时断电又上电的方式,使故障节点重启,这种方式需要硬件支持。
主节点在某一端时间由于某种原因,没时间传递心跳信息,这个时候集群会选取新的 DC,从新分配资源提供服务,如果主节点服务器还没有宕掉,这样就会导致服务器分隔、资源争用,这种情况被称为脑裂 (brain-split)。此时,用户能访问,一旦有写的操作,就会导致文件系统崩溃,损失惨重。为避免这种情况,新的 DC 一旦产生,第一时间对主节点执行 stonith,这种操作叫做资源隔离。
4、高可用集群工作模型
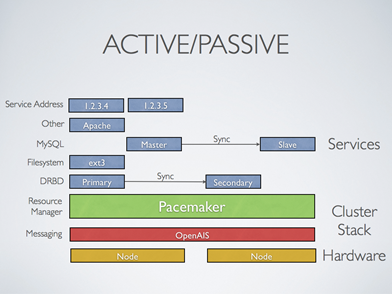
4-1、Active/Passive:主备模型
一个活动主节点,另一个不活动作为备用节点,当主节点故障,转移到备节点,这时备节点就成为了主节点。备节点完全冗余,造成一定浪费。如下图,MySQL、DRBD 主从节点间还要进行同步:
4-2、Active/Active:双主模型
两个节点都是活动的,两个节点运行两个不同的服务,也互为备用节点。也可以提供同一个服务,比如 ipvs,前端基于 DNS 轮询。这种模型可以使用比较均衡的主机配置,不会造成浪费。
4-3、N+1
N 个活动主节点 N 个服务,一个备用节点。这需要额外的备用节点必须能够代替任何主节点,当任何主节点故障时,备节点能够负责它的角色对外提供相应的服务。如下图,最后一个备用节点可以作为前两台主节点的 DRBD 和第三台主节点的 MYSQL 提供备用功能:
4-4、N+M
N 个活动主节点,M 个备用节点。像上面的 N+1 模型,一个备用节点可能无法提供足够的备用冗余能力,备用节点的数量 M 是成本和可靠性要求之间的折衷。
也有一种说法:N-M: N 个节点 M 个服务, N>M, 活动节点为 N, 备用节点为 N-M。
4-5、N-to-1
这和 N+1 一样,也是 N 个活动主节点,一个备用节点;不同是的备用节点成为主节点只是暂时的,当原来故障的节点修复后,必须回转才能正常工作。
4-6、N-to-N
N 个主节点 N 个备用节点。这是 A/A 双主和 N + M 模型的组合,N 节点都有服务,如果一个坏了,剩下的每个节点都可以作为替代提供服务。如下图,当共享存储是可用的,每一个节点都可能会被用于故障切换。起搏器甚至可以运行服务的多个副本,以分散工作量。

5、高可用集群架构层次
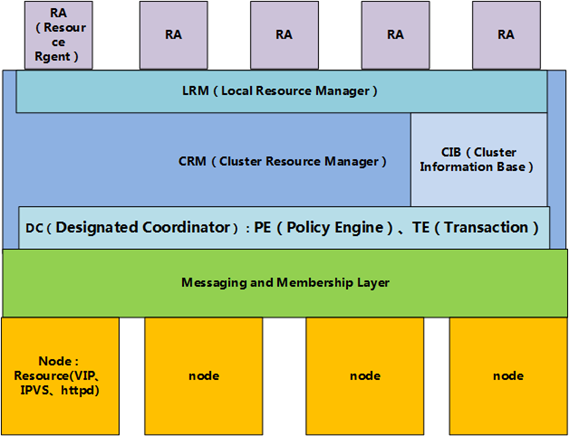
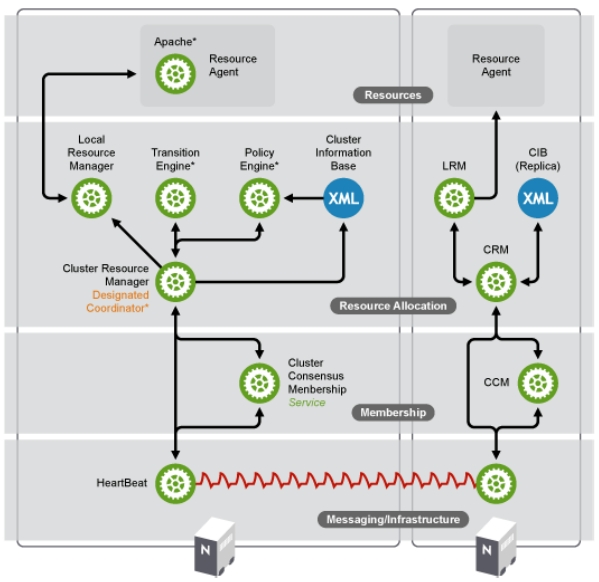
5-1、节点主机层
这一层主要是正在运行在物理主机上的服务,高可用集群相关的软件运行在各主机上,集群资源也是在各主机上。
5-2、Messaging and Membership Layer(成员消息层)
5-2-1 信息传递层
传递集群信息的一种机制,通过监听 UDP 694 号端口,可通过单播、组播、广播的方式,实时快速传递信息,传递的内容为高可用集群的集群事务,例如:心跳信息,资源事务信息等等,只负责传递信息,不负责信息的计算和比较。
心跳信息:集群中每一台服务器都不停的将自己在线的信息通告给集群中的其他主机。
心跳信息的传递是基于套接字通信的,通过软件提供服务监听套接字,实现数据发送、请求。必须安装软件,并开启服务,这是实现高可用集群的基础。
5-2-2 成员关系(Membership)层
这层最重要的作用是主节点(DC)通过 Cluster Consensus Menbership Service(CCM 或者 CCS)这种服务由 Messaging 层提供的信息,来产生一个完整的成员关系。CCM 的作用,承上启下,监听底层接受的心跳信息,当监听不到心跳信息的时候就重新计算整个集群的票数和收敛状态信息,并将结果转递给上层,让上层做出决定采取怎样的措施。CCM 还能够生成一个各节点状态的拓扑结构概览图,以本节点做为视角,保证该节点在特殊情况下能够采取对应的动作。
Messaging & Membership 一般由同一软件实现。
5-3、资源分配层 (Resource Allocation)
也叫资源管理器层,真正实现集群服务的层。包含 CRM(集群资源管理器,cluster Resource Manager),CIB(集群信息基库,Cluster Infonation Base),PE(策略引擎,Policy Engine),TE(实施引擎,Transition Engine), LRM(Local Resource Manager,本地资源管理器)
- CRM 组件
CRM(Cluster Resource Manager),核心组件,实现资源的分配和管理。它需要借助 Messaging Layer 来实现工作,因此工作在 Messaging Layer 上层。每个节点上的 CRM 都维护一个 CIB 用来定义资源特定的属性,哪些资源定义在同一个节点上。主节点上的 CRM 被选举为 DC (Designated Coordinator 指定协调员,主节点挂掉会选出新的 DC),成为管理者,它的工作是决策和管理集群中的所有资源。
任何 DC 上会额外运行两个进程,一个叫 PE,;一个叫 TE。
PE :定义资源转移的一整套转移方式,但只做策略,并不亲自来参加资源转移的过程,而是让 TE 来执行自己的策略。
TE : 就是来执行 PE 做出的策略的并且只有 DC 上才运行 PE 和 TE。
资源管理器的主要工作是收集 messaging Layer 传递的节点信息,并负责信息的计算和比较,并做出相应的动作,如服务的启动、停止和资源转移、资源的定义和资源分配。
- CIB 组件
XML 格式的配置文件,工作的时候常驻内存。集群的所有信息都会反馈在 CIB 中。在每一个节点上都包含一个 CRM,且每个 CRM 都维护这一个 CIB(Cluster Information Base,集群信息库),只有在主节点上的 CIB 是可以修改的,其他节点上的 CIB 都是从主节点那里复制而来的。
DC 组件
CRM 会推选出一个用于计算和比较的节点,叫 DC(Designated coordinator)指定协调节点,计算由 PE(Policy Engine)策略引擎实现,计算出结果后的动作控制由 TE(Transition Engine)事务引擎实现。
LRM 组件
在每个节点上都有一个 LRM(local resource manager)本地资源管理器,是 CRM 的一个子功能,接收 TE 传递过来的事务,在节点上采取相应动作,如运行 RA 脚本等。
5-4、RA(Resource Rgent)
资源代理层,简单的说就是能够对集群资源进行管理的脚本,如启动 start,停止 stop、重启 restart 和查询状态信息 status 等操作的脚本。LRM 本地资源管理器负责运行。
资源代理分为:
- Legacy heartbeat(heatbeat v1 版本的资源管理);
- LSB(Linux Standard Base),主要是 /etc/init.d/* 目录下的脚本,start/stop/restart/status;
- OCF(Open Cluster Famework),比 LSB 更专业,更加通用,除了上面的四种操作,还包含 monitor、validate-all 等集群操作,OCF 的规范在 http://www.opencf.org/cgi-bin/viewcvs.cgi/specs/ra/resource-agent-api.txt?rev=HEAD。
- STONITH:实现节点隔离
6、高可用集群软件
6-1、Messaging Layer 集群信息层软件
- heartbeat (v1, v2)
- heartbeat v3 可以拆分为:heartbeat, pacemaker, cluster-glue
- corosync 从 OpenAIS 分离的项目。
- cman
- keepalived 一般用于两个节点的集群
- ultramokey
6-2、Cluster Resource Manager Layer(资源管理层)
\1. Haresource
heartbeat v1 v2 包含,使用文本配置接口 haresources
\2. crm
heartbeat v2 包含,可以使用 crmsh 或者 heartbeat-gui 来进行配置
\3. pacemaker
heartbeat v3 分离出来的项目,配置接口:CLI:crm、pcs 和 GUI:hawk (WEB-GUI)、LCMC、pacemaker-mgmt、pcs
\4. rgmanager
cman 包含,使用 rgmanager (resource group manager) 实现管理,具有 Failover Domain 故障转移域这一特性,也可以使用 RHCS(Redhat Cluster Suite)套件来进行管理:Conga 的全生命周期接口,Conga(luci/ricci)先安装后,可用其安装高可用软件,再进行配置。
6-3、常用组合
heartbeat v2+haresource (或 crm) (说明:一般常用于 CentOS 5.X)
heartbeat v3+pacemaker (说明:一般常用于 CentOS 6.X)
corosync+pacemaker (说明:现在最常用的组合)
cman + rgmanager (说明:红帽集群套件中的组件,还包括 gfs2,clvm)
keepalived+lvs (说明:常用于 lvs 的高可用)
7、共享存储
高可用集群多节点都需要访问数据,如果各节点访问同一个数据文件都是在同一个存储空间内的,就是说数据共享的就一份,而这个存储空间就共享存储。
如 Web 或 MySQL 高可用集群,他们的数据一般需要放在共享存储中,主节点能访问,从节点也能访问。当然这也不是必须的,如可以通过 rsync、DRBD 来同步分别存储在主、从节点上的块数据,而且相对共享存储实现成本更低,具体使用什么需要根据实际场景来选择。下面我们就简单说一下共享存储的类型:
7-1、DAS(Direct attached storage,直接附加存储)
存储设备直接连接到主机总线上的,距离有限,而且还要重新挂载,之间有数据传输有延时;
这是设备块级别驱动上实现的共享,持有锁是在节点主机本地上的,无法通知其他节点,所以如果多节点活动模型的集群同时写入数据,会发生严重的数据崩溃错误问题,主备双节点模型的集群在分裂的时候了会出现问题;
常用的存储设备:RAID 阵列、SCSI 阵列。
7-2、NAS(network attached storage,网络附加存储)
文件级别交互的共享,各存储设备通过文件系统向集群各节点提供共享存储服务,是用 C/S 框架协议来实现通信的应用层服务。
常用的文件系统:NFS、FTP、CIFS 等,如使用 NFS 实现的共享存储,各节点是通过 NFS 协议来向共享存储请求文件的。
7-3、SAN(storage area network、存储区域网络)
块级别的,将通信传输网络模拟成 SCSI(Small Computer System Interface)总线来使用,节点主机(initiator)和 SAN 主机(target)都需要 SCSI 驱动,并借助网络隧道来传输 SAN 报文,所以接入到 SAN 主机的存储设备不一定需要是 SCSI 类型的。
常用的 SAN:FC 光网络(交换机的光接口超贵,代价太高)、IPSAN(iscsi、存取快,块级别,廉价)。